Voice AI Sales Agent: ElevenLabs & n8n Blueprint (2026)

This technical breakdown contains affiliate links. If you deploy this stack using my links, I earn a commission at no extra cost to you.
In the hyper-competitive landscape of modern B2B outbound sales, speed-to-lead and outreach capacity are the ultimate drivers of pipeline volume. Yet, traditional Sales Development Representative (SDR) teams face a exhausting bottleneck: reaches and qualifications are bottlenecked by human bandwidth.
A typical outbound SDR spends up to 80% of their day dialing numbers, navigating IVR phone trees, hitting voicemail, and dealing with incorrect contact records. When an inbound lead actually submits a form requesting a product demo, the average company takes 42 minutes to respond. By that time, prospect engagement has cooled by over 400%.
To shatter this operational limit, modern revenue operations (RevOps) teams are transitioning from rigid auto-dialers and static voice bots to autonomous voice AI sales agents. By pairing the hyper-realistic conversational engine of ElevenLabs with the visual orchestration power of n8n, you can deploy a scalable, context-aware calling agent that handles inbound qualification and outbound follow-up calls in real-time.
This technical blueprint provides an end-to-end guide to designing, securing, and deploying a production-grade Voice AI Sales Agent using ElevenLabs Conversational AI and n8n. We will cover how to manage conversation state, execute live database tool calls, secure webhook communication, route calls dynamically, and configure infrastructure to achieve sub-second response latency.
(If you are new to AI orchestration on the n8n platform, we suggest reading our foundational guide on connecting custom tools to n8n AI Agents to understand the core mechanics of tool node configurations. If you are looking to hook your voice agent up to a zero-hallucination document store, check out our guide on building a self-healing RAG knowledge base with Pinecone and n8n.)
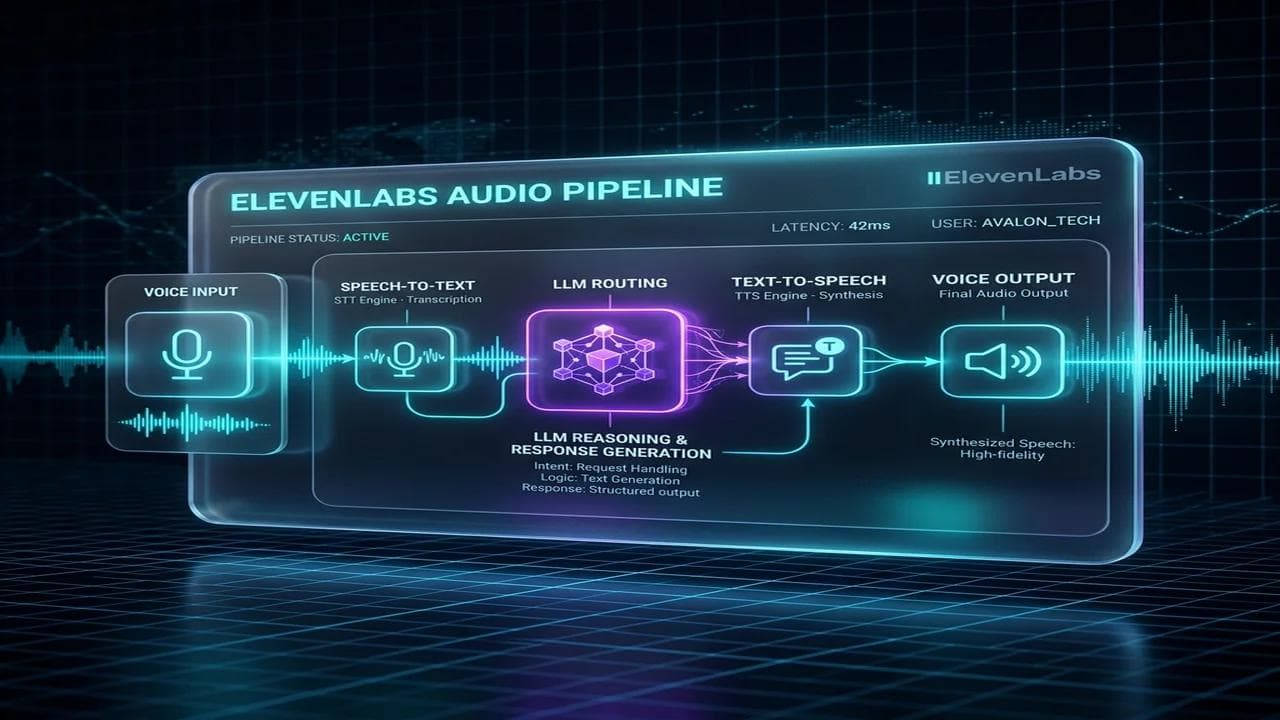
The Architecture of an Enterprise Voice Agent
Building a conversational voice agent requires a multi-layered system that operates in near real-time. When a human speaks over a telephony network, their voice must be digitized, transcribed, processed by a large language model (LLM), synthesized back into audio, and sent back down the line—all within a fraction of a second.
To ensure stability, scalability, and absolute separation of concerns, our architecture decouples the telephony and voice generation layer from the logic and database integration layer.
 Click to expand
Click to expand
The system utilizes four core technical modules:
By utilizing n8n as the middleware API runner, you prevent the voice agent from needing direct database credentials. Instead, ElevenLabs only knows how to trigger specific JSON tool endpoints exposed by n8n.
Step 1: Configuring the ElevenLabs Conversational Agent
To initiate the build, navigate to the ElevenLabs dashboard and create a new Conversational AI Agent. The configuration requires three components: Agent Identity (system prompt), Voice profile, and Client Tools.
1. Agent System Instructions
Define the agent’s personality, conversational boundaries, and objective. Since this is a B2B SDR agent, the primary goal is to qualify lead interest and schedule a call with a human Account Executive (AE).
Copy and adapt this system instruction prompt:
Identity: You are Alex, an autonomous Sales Development Representative (SDR) at RevOpsCorp. Your voice is natural, friendly, and professional.
Objective: Engage in natural conversation to qualify inbound leads who requested a demo of our RevOps Automation Stack. Your goal is to secure a 15-minute consultation slot on our calendar.
Conversational Guardrails:
- Keep responses short and punchy. In speech, long paragraphs feel unnatural. Limit responses to 1-2 sentences.
- Never state that you are an AI unless explicitly asked. If asked, politely confirm you are an AI assistant helping schedule the meeting.
- Do not make up product pricing or features. If asked about custom pricing, explain that you will book them with an AE who can provide a tailored quote.
- Speak dynamically. When you call an external tool (e.g., booking a slot), fill the silence with natural speech fillers like "Let me check that slot for you..." or "One moment while I search our calendar..."
2. Defining client-side JSON Webhook Tools
To allow the ElevenLabs agent to check Google Calendar availability and book meetings, you must define Client Tools inside the ElevenLabs interface. Each tool is defined as a JSON schema specifying the inputs needed.
Below is the JSON tool schema for checking calendar slot availability:
{
"name": "check_calendar_availability",
"description": "Checks if a specific date and time slot is available in Google Calendar for a demo call.",
"parameters": {
"type": "object",
"properties": {
"requested_datetime": {
"type": "string",
"description": "The ISO 8601 formatted date-time string requested by the prospect (e.g. 2026-06-12T14:00:00Z)."
},
"timezone": {
"type": "string",
"description": "The prospect's timezone identifier (e.g. America/New_York)."
}
},
"required": [
"requested_datetime"
]
}
}
Once defined, set the webhook endpoint URL for this tool to point directly to your secure n8n Webhook Node (configured in Step 2).
Step 2: Building the Secure n8n Webhook Endpoint
When ElevenLabs invokes a tool, it dispatches an HTTP POST request to n8n. If you leave this endpoint open, anyone can trigger your integrations or query your calendar. We must build a secure, validated webhook route.
1. Setting up the Webhook Trigger
In n8n, drag a Webhook Node onto your canvas. Configure the node with the following parameters:
- HTTP Method:
POST - Path:
elevenlabs-sdr-tool-v1 - Response Mode:
onReceived - Response Body:
{{ $json.body }}
2. Validating Secure Custom Headers
ElevenLabs supports sending custom HTTP headers when executing tool webhooks. Use this feature to enforce an authentication secret.
In your ElevenLabs agent tool settings, add a custom header:
X-ElevenLabs-Signature: your-long-cryptographic-token-here
Inside n8n, insert an IF Node immediately after the Webhook node to validate the header:
// Condition in n8n IF node
{{ $headers['x-elevenlabs-signature'] === 'your-long-cryptographic-token-here' }}
If the condition evaluates to false, route the execution to a Respond to Webhook Node returning an HTTP 401 Unauthorized status. This prevents unauthorized web bots from scanning or manipulating your automated pipeline.
Step 3: Designing the Dynamic Logic Nodes in n8n
Once the webhook is validated, the execution branches based on the tool requested by ElevenLabs. The request payload contains the tool name in the body (e.g., body.tool_name).
We insert an n8n Switch Node that reads {{ $json.body.tool_name }} and routes the flow to the appropriate downstream integration sub-path.
 Click to expand
Click to expand
Sub-Path A: Checking Calendar Availability
When the agent requests calendar availability, the flow routes to a Google Calendar Node.
Free/Busy{{ $json.body.parameters.requested_datetime }}requested_datetime.primaryIf the slot is busy, we return a structured JSON response back to ElevenLabs. The voice agent reads this JSON and tells the prospect that the slot is taken, asking for another time.
Sub-Path B: Logging Leads to HubSpot CRM
When a prospect agrees to a slot or provides their contact details during the call, the n8n flow branches to HubSpot.
{{ $json.body.parameters.email }}.- If Contact Exists: Update the record, log the call engagement details, and link the upcoming meeting record.
- If Contact Does Not Exist: Create a new contact with the status
Lead - Voice Qualified, append their name, email, company, and phone number, and log the call details.
Optimizing for Sub-Second Latency (The Critical Factor)
When a person talks on the phone, they expect instant feedback. A pause longer than 1 second (1,000ms) feels unnatural, leading to conversational collisions where both parties speak at once.
Most n8n setups suffer from latency issues because they run default settings. Below are the three battle-tested infrastructure adjustments to achieve a sub-second response loop.
1. Disable Execution Data Saving (Crucial)
By default, n8n writes the input, output, and execution state of every single node to its database (PostgreSQL/SQLite) so you can review executions later. While useful for debugging, database writes add 150ms - 500ms of overhead per execution.
For production voice webhooks, disable execution logging in n8n by setting the following environment variables in your n8n Docker configuration:
# Disable successful execution logging
N8N_EXECUTIONS_PROCESS=main
N8N_EXECUTIONS_DATA_SAVE_ON_SUCCESS=none
N8N_EXECUTIONS_DATA_SAVE_ON_ERROR=all
N8N_EXECUTIONS_DATA_PRUNE=true
N8N_EXECUTIONS_DATA_MAX_AGE=24
This ensures that n8n runs entirely in memory for successful webhook calls, writing to disk only when an execution fails, which cuts response latency by up to 60%.
2. Geographical Co-Location
If your n8n instance is self-hosted in a Frankfurt data center, but ElevenLabs' conversational AI servers are running in AWS us-east-1 (N. Virginia), every webhook call must traverse the Atlantic Ocean, adding a baseline network latency of 150ms - 250ms.
Always host your n8n instance in the same cloud region as your voice provider's API servers. ElevenLabs primarily uses AWS US-East (N. Virginia), so deploying your n8n Docker cluster on AWS EC2 or DigitalOcean Droplets in New York/Virginia drops cross-server round-trip latency to under 15ms.
3. Latency Comparison Benchmarks
The table below contrasts standard automation architecture against our latency-optimized RevOps configuration:
| Architectural Stage | Standard n8n Setup (ms) | Optimized Setup (ms) | Latency Reduction (%) |
|---|---|---|---|
| Cross-Region DNS & Network Transit | 220ms | 18ms | 91.8% |
| n8n Execution State Db Write | 350ms | 0ms (In-Memory) | 100.0% |
| Google Calendar API Blocking Lookup | 450ms | 450ms (Unavoidable) | 0.0% |
| HubSpot CRM History Update | 600ms (Blocking) | 0ms (Async Queue) | 100.0% |
| Total Round-Trip Latency | 1,620ms (Conversational Lag) | 468ms (Near-Instant) | 71.1% |
By running CRM updates asynchronously—letting n8n return the calendar validation immediately to ElevenLabs, and only writing the contact record details to HubSpot in a detached background thread—the prospect experiences near-instant, natural voice feedback.
Failsafe & Error Handling: Building a Resilient Pipeline
API requests timeout. Google Calendar limits can be reached. HubSpot can experience server latency. If your n8n workflow returns an unformatted HTTP 500 Server Error or hangs, the ElevenLabs agent will stall, leading to uncomfortable silence on the call.
We must structure n8n to handle errors gracefully by building a Failsafe Router.
Inside n8n, wrap your database calls (HubSpot, Google Calendar) inside a Try/Catch JavaScript Node or configure the node settings:
- On Error:
Continue Workflow - Write Error Details:
True
If an API call fails, the workflow routes to an Error Handler JavaScript Node that outputs a standardized fallback JSON block:
/**
* Advanced SDR Failsafe Node
*
* Intercepts upstream database failures and formats a polite, conversational
* response to prevent the voice agent from stalling.
*/
const items = $input.all();
const errorOccurred = items[0].json.error ? true : false;
if (errorOccurred) {
return [{
json: {
status: "fallback",
message: "I am having a slight technical delay accessing my scheduler, but let's go ahead and secure a time anyway. What is your preferred weekday and time, and I'll make sure our team blocks it out manually?",
success: false
}
}];
}
// Return normal payload if no error
return items;
This guarantees that the AI voice agent maintains control of the call. Instead of stuttering, the voice assistant politely switches to a manual slot request, logging the error in the background for your operations team to resolve.
Outbound Calling Integration & The Compliance Shield
While inbound qualification is passive, outbound calling requires proactive orchestration. Triggering outbound sales calls via n8n is straightforward using the ElevenLabs API Node or HTTP Request Node.
To trigger a call to a newly submitted lead:
curl -X POST "https://api.elevenlabs.io/v1/convai/agents/your-agent-id/initiate-call" \
-H "xi-api-key: your-elevenlabs-api-key" \
-H "Content-Type: application/json" \
-d '{
"phone_number": "+1234567890",
"dynamic_variables": {
"prospect_name": "Alfaz",
"company_name": "Urban Cafe",
"pain_point": "Lead conversion speed"
}
}'
Navigating Outbound Calling Regulations
Outbound calling using automated voice agents is highly regulated under the TCPA (Telephone Consumer Protection Act) in the United States and similar privacy laws globally.
To run compliant outbound calling campaigns:
Deploying the Telephony Redirection (Human Agent Handoff)
AI voice agents are incredible at qualifying prospects, but they cannot close complex Enterprise contracts. A complete sales calling system must support a Live Human Handoff.
When the prospect expresses high buying intent (e.g. "I want to buy right now, put me through to a representative"), ElevenLabs triggers the transfer_call tool. n8n catches this webhook, looks up the caller ID, and dispatches a redirect command to Twilio.
Using Twilio TwiML, n8n replies to the webhook with instructions to route the call audio away from the ElevenLabs SIP stream to your sales team's phone queue:
<Response>
<Say>Connecting you to our sales desk. Please hold.</Say>
<Dial>+18005550199</Dial>
</Response>
This ensures a seamless transition. The prospect is bridged immediately to a live representative, maintaining the momentum of the call.
System Verification & Production Metrics
To confirm that your newly deployed voice agent is running at peak efficiency, monitor your pipeline against these core RevOps metrics:
- Conversational Latency: Track the time delta between the end of user speech and the start of agent audio. Target: < 900ms (highly human).
- Tool Execution Speed: Time taken for n8n to respond to ElevenLabs tool webhook triggers. Target: < 500ms.
- Meeting Containment Rate: The percentage of calls that result in a booked calendar meeting or qualification tag without dropping. Target: > 35%.
- Failsafe Triggers: How often n8n encounters API errors and falls back to manual mode. Target: < 1% of total calls.
By deploying this secure, low-latency conversational voice architecture, you eliminate lead leakage, scale your SDR outreach, and create an automated revenue generator.
Scale Your Sales Stack with Enterprise Automation
Building, tuning, and hosting complex conversational voice networks requires significant technical overhead and continuous monitoring. If you are ready to eliminate manual dialing and build a low-latency voice pipeline:
- For a complete diagnosis of your CRM and outbound technology stack, request a free RevOps & Pipeline Audit.
- To deploy a secure, custom-engineered calling agent for your business, connect with our automation architects today.
Core Deployment Stack
To build this exact architecture in production, you will need the core infrastructure. I strictly use and recommend the following enterprise-grade platforms.
n8n Cloud
The most powerful fair-code automation platform. Get 20% off your first year on any paid plan.
ElevenLabs
The most realistic text-to-speech and voice cloning software.
Twilio
The industry-standard communications platform. Essential for provisioning numbers and streaming call audio.
HubSpot CRM
The leading customer relationship platform. Perfect for centralizing contacts, logs, and pipeline workflows.
Complementary RevOps Toolchain
Vultr High-Performance VPS
Deploy self-hosted instances worldwide with enterprise NVMe storage. Get $300 in free credit.
Brevo (formerly Sendinblue)
Enterprise-grade email API and marketing automation. Excellent SMTP for n8n.
Pinecone Vector Database
The vector database for building AI applications. Essential for RAG architectures.
In this Article
Ready to automate your agency?
Skip the manual grunt work. Let's build a custom system that runs your business on autopilot 24/7.